 R语言与基础计量
R语言与基础计量type
status
date
slug
summary
tags
category
icon
password
Preface
- References
- 入门级别 The Effect: An Introduction to Research Design and Causality Causal Inference: The Mixtape Introduction to Econometrics with R
- 专业级别 Statistical Tools for Causal Inference
- 学者博客 数据科学中的R语言(四川师范大学课程 ) 数据科学与 R 语言 Software - Yiqing Xu
- 因果检验 [[Fixed Effects]] [[Event Studies]] [[Instrumental Variables]] [[Regression Discontinuity]] [[Difference-in-Difference]]
- Important Packages
- Summary Models: modelsummary, gtsummary
- Plot Results: sjPlot
The question isn’t whether you’ve omitted anything, it’s how important the omission is.
Your last line of defense is your gut.
如果你在直觉上感觉都有些不对劲,那大概率是错的。
- Begin with a question, a GOOD question
- 这个问题是可以回答的,最好是可以通过数据获得答案
- 这个问题的答案,有助于我们理解世界运行的规律,也就是具有理论性
- 我对这个问题的可能结果,有着初步的认识,感性的、理论的认识
- 这个问题是可行的,我有能力去收集数据,数据的来源是可靠、准确的
- 我为了检验答案所设计的研究是合理的
- 尽量让问题简单化
- Describe variables 当一个数据左偏或者右偏时,可以使用log让其变正态
- Identification Find Data Generating Process DGP That process - finding where the variation you’re interested in is lurking and isolating just that part so you know that you’re answering your research question - is called identification.
- Using theory, paint the most accurate picture possible of what the data generating process looks like
- Use that data generating process to figure out the reasons our data might look the way it does that don’t answer our research question
- Find ways to block out those alternate reasons and so dig out the variation we need
- Casual Diagrams 对于因果的识别,来源于既往的文献、理论以及现实经验 变量间的复杂关系会导致因果图趋于复杂 精简因果图:
- 去掉不重要的
- 去掉冗余的
- 去掉中介的,如果A-B-C的路径上,再没有别的变量影响,可以考虑精简为A-C
- 去掉无关的变量
- Front Doors and Back Doors 我们希望识别的效应都是从x出发走到y,这就是前门 然而,总有一些变量,他可能同时对x和y产生影响,m到x的路径就是后门 控制变量的目的就是关闭后门,留下前门
A. Regression
💡 寻找与主效应相关的变量,将他们都控制住
1. Error Terms / Residual
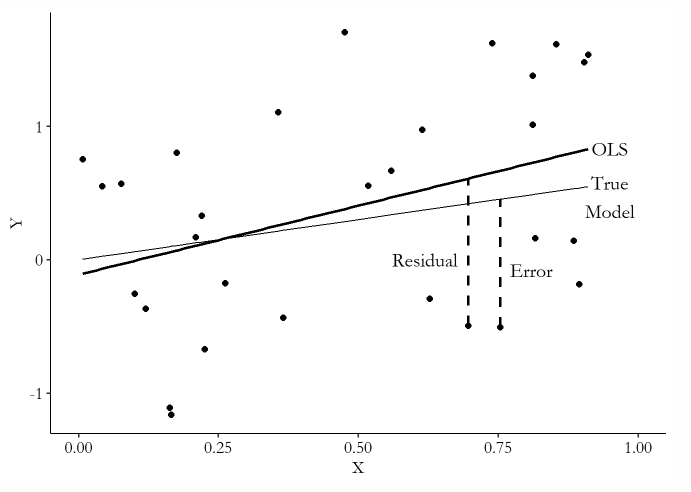
拟合模型中未知的部分就是Residual,未知的部分则是Error
Error是由于模型的局限而导致的,Residual则还包括了样本的局限
由此,引出了外生性假设
假设1:外生性假设 Exogeneity Assumption If we want to say that our OLS estimates of will, on average, give us the population , then it must be the case that is uncorrelated with . 与 不相关,不意味着二者完全无关,这里的不相关只是指二者没有线性关系 与前面的研究设计部分相对应,外生性假设要求我们关闭因果图中的所有后门,仅留前门 换句话说,我们需要尽可能将那些影响较为直接的因素考虑在模型中 当 中与 直接具有线性关系时,通常会认为我们在模型中遗漏了一些重要变量 同时,我们遗漏一些东西是没事的——我们总会遗漏一些, 只要他与 无关就行
2. Hypothesis Testing
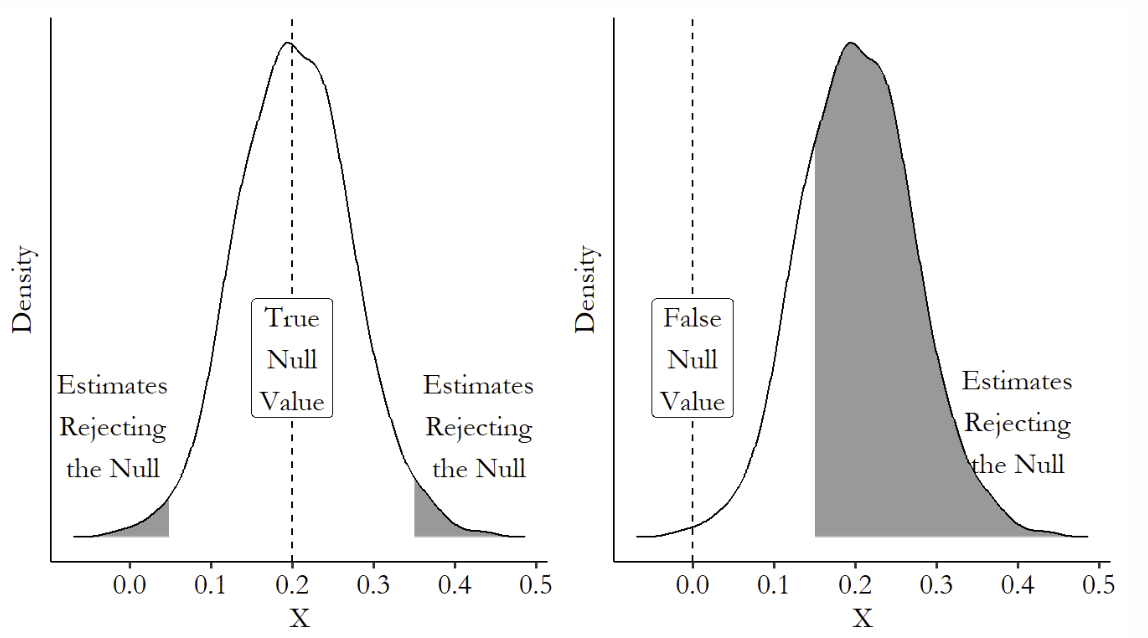
假设检验提供了一个捷径,我们通过拒绝 来告诉别人我的模型是对的
但是,不具有显著性的变量,不意味着他的估计就是错的,他只是在统计上不重要
不要通过修改数据来获得显著性
Never P-hacking
此外,显著性通过不意味着估计真实,如果标准误很大,那么研究结论很可能是一个侥幸
最后,显著性不是研究的全部,研究结论的重要与否更取决于你的故事
3. Variables
- 离散变量 Discrete Variable 虚拟变量,注意分类变量是与某一类别比,可用联合检验考察
- 多项式 Polynomials 通过观察 的散点图,如果需要多项式,那么图案应当具有规律性
- 变量转换 Variable Transformations 对 X 取对数:当变量有偏,尤其是右偏的时候可以通过取对数让分布正态 对 Y 取对数:让回归线性 取平方根:类似于取对数,与对数相比这个变换还能接受0 反双曲正弦变换 Inverse Hyperbolic: 可以接受0和负数 尾部处理 Winsorizing:专门用于处理异常值,将X%之后的值都替换为X%上的值 标准化 Standardizing:,目的是使模型易于解释
- 交互项 Interaction Terms X 对 Y 的影响: 一旦加入了交互项,单个系数可能会变得奇怪,需要将交互项都综合考虑进来
- 非线性回归 Nonlinear Regression 广义线性回归 Generalized Liner Models: 逻辑回归 Logit Link: 泊松回归 Probit Link:累积分布函数 使用 GLM 后,很难继续对系数进行更准确的描述,增加对需要通过边际效应求解
- Marginal Effect at the Mean 取所有变量来
- Average Marginal Effect
4. Standard Errors
假设2:正态假设 Normally Distributed The error term itself must be normally distributed. 不过这个假设不重要
假设3:独立同分布 Independent and Identically Distributed The theoretical distribution of the error term is unrelated to the error terms of other observations and the other variables for the same observation (independent) as well as the same for each observation (identically distributed)
- 异方差下的标准误修正:Sandwich Estimator 和 Huber-White Standard Errors
- 时间自相关下:Heteroskedasticity- and Autocorrelation-Consistent (HAC) Standard Errors、Newey-West estimator
- Hierarchical Structure:clustered standard errors、Liang-Zeger standard errors
- 最后,Bootstrap,解决样本偏误问题的最完美的标准误
5. Additional Regression Concerns
- 样本权重 Sample Weights 当样本有偏时,可以通过调整权重来控制样本的分布
- 共线性 Collinearity 一般情况下不会有完美的共线问题,但是当两个变量间 VIF 高于 0.9 时还是需要处理一下 VIF 高于 0.9 指的是 ,回归发现 大于 0.9
- 测量误差 Measurement Error 经典测量误差可以不用处理 而当测量误差与自变量相关时,则需要进行处理
- 惩罚回归 Penalized Regression
B. Matching
💡 找到一个除了主效应外,没有其他变化的样本
1. Weighted
匹配体现在数据表中,通过加权的方式来影响数据的生成与回归的结果
- 常见的匹配方式 One-to-One Matching, K-Nearest-Neighbor Matching, Radius Matching 一对一匹配将更多的引入偏差,半径匹配则将引入更多的方差 当控制组和对照组数量相当时,可以考虑使用一对一匹配,或者1对k匹配 当控制组数量远高于对照组时,可以考虑1对K匹配,或者半径匹配
- 计算匹配值的两种方式 Mahalanobis Distance: Propensity Score Matching
- 计算权重的两种方式 Kernel-based Weighting: Inverse Probability Weighting : 不过逆概率加权的方式,在处理接近0、1的概率时会出问题,需要进行处理 常见的方法是将倾向得分转化为优势比,然后再计算 P 计算半径的带宽,一般是匹配值的标准差,精确匹配的带宽则为0
2. Mahalanobis Distance Matching
基于 Mahalanobis Distance 的传统距离匹配
3. Coarsened Exact Matching
Mahalanobis Distance 忽略了一些变量的作用,他会删除一些变量
如果我们假设所有的变量都很重要,就需要进行精确匹配
然而精确匹配要求距离为0,对于连续变量而言几乎不肯能有距离为0的变量
因此有必要先对变量进行粗化,将其作为类似类别的变量再进行匹配
4. Entropy Balancing
5. Propensity Score Matching
6. Estimation with Matched Data
C. Simulation
1. Why We Simulate
测试估计在特定的样本中是否会有真正的效果,进而了解估计的抽样分布
同时,可以看到估计对某些假设的敏感性。验证某一假设不成立时,估计的有效性
2. Coding
创建数据